I previously touched on how I use CarPlay and I promised to provide some details on how I configure and use Home Assistant with CarPlay. For this to work, you must have the Home Assistant companion app installed from the App Store. Also, although I will not directly discuss the Android based app and Android Auto, it is my understanding that all of this is the same or very similar on that platform. Once the companion app is installed, Home Assistant will be shown as an icon on your car display. Opening the app will show you some (configurable) options include one for Quick Access. The Quick Access is where I am concentrating today.
My personal use case for how to use Home Assistant through CarPlay is, while limited, a huge quality of life improvement. I have also previously discussed the Rage Against the Garage Door Opener (RATGDO) device which allows me to tie my Chamberlain based garage door openers into Home Assistant. The CarPlay integration is huge because it allows me to control the garage doors extremely reliably unlike when I use the official remote. My house is wrapped in foil lined insulation as well as metal siding which greatly attenuates the RF signal from the remote leading to some very frustrating moments trying to get doors to open or close. As long as my phone has an internet connect, I can see the status of and control both garage doors on the house without issue.
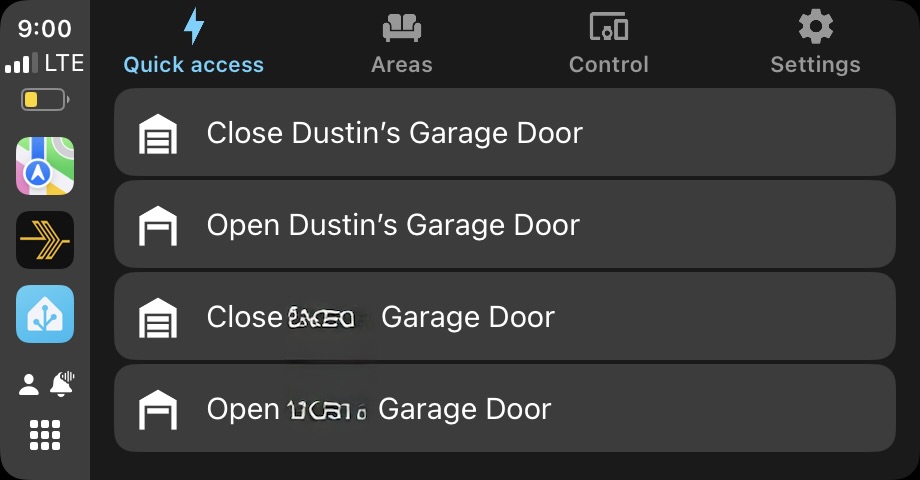
Out of the box, you will see four icons across the top of the screen when you start Home Assistant. Personally, I find the default setup to be cumbersome and confusing but that would be more about how I have my Home Assistant configured than anything.
Let’s setup a Quick Action. To get started, first open the companion app and find settings. Then open CarPlay (or Android Auto)
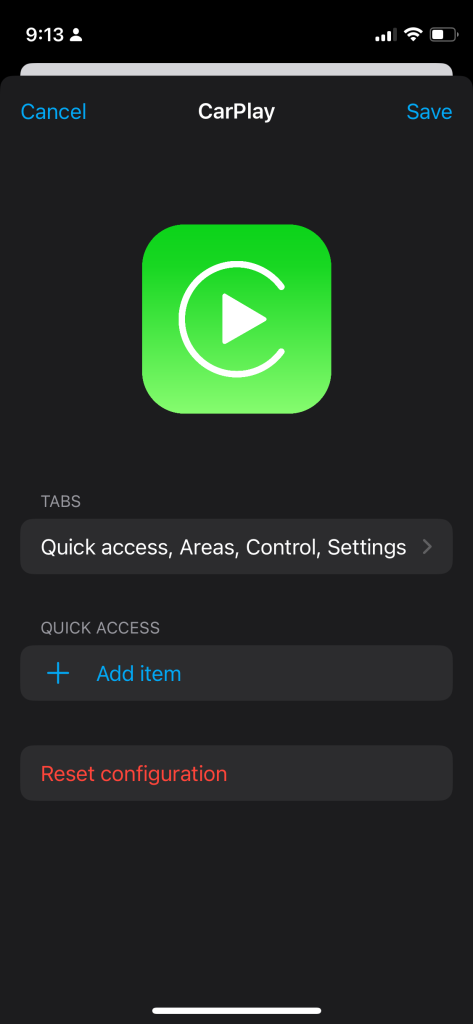
You can use the Tabs fly out to configure what tabs appear on your car display and in what order. To add an item to Quick Actions tap on Add item.
Here is where you can add specific entities, scripts, scenes or iOS Actions. iOS Actions is a deprecated way of adding items to CarPlay and unless you specifically need to have actions for your iOS device, I would avoid setting them up as it requires a lot of extra steps. For my use case, I simply want to have quick access to my garage doors so I am adding those entities directly by searching for the name of the entity.
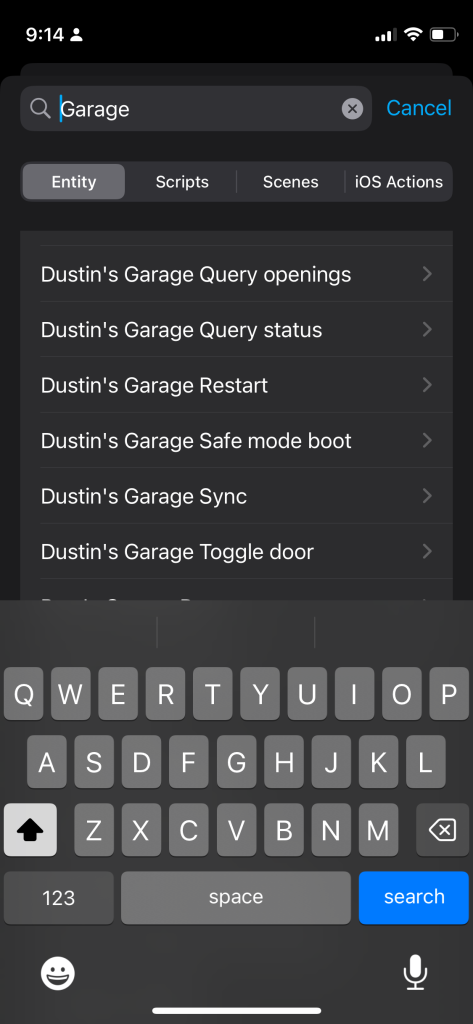
This is where it can be tricky because a number of entities can have the same name but be different resources in Home Assistant. In fact, it took me a bit of trial and error to find that I wanted to add “Dustin’s Garage Door” that had the “curtain” icon. This entity, with the oddly chosen icon, is the correct one to control the door. On this screen, you can also customize what the icon color will be as well is if you want to require confirmation before performing the action.
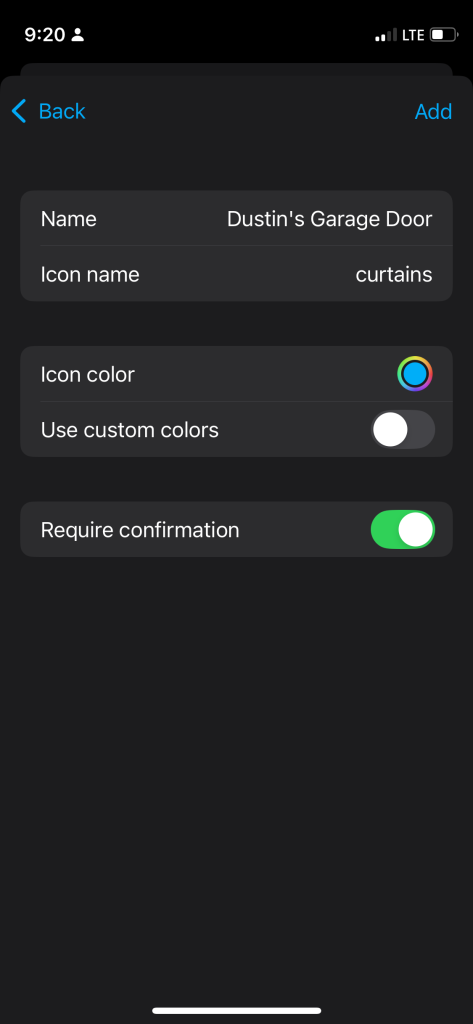
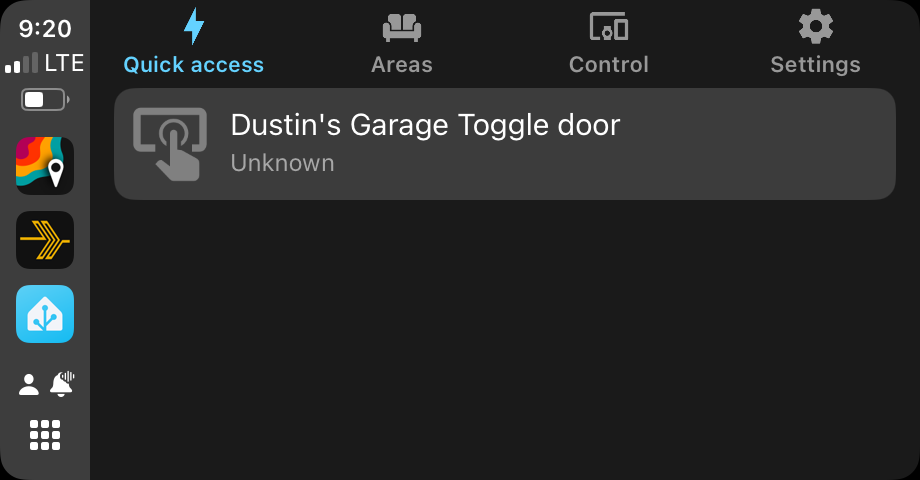
After making your selections tap on add. Once added, save your settings and the next time you connect to CarPlay you will have access to your chosen entities. Below is a screenshot showing that I can see the status of my door as well as control it by simply tapping on it.
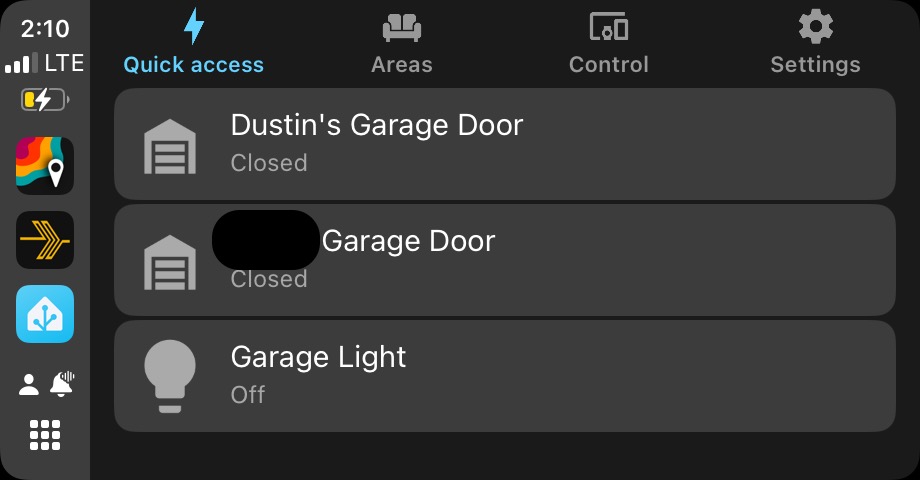
You can add any entity, script or scene to quick actions and as many as you are willing to scroll the screen through. Having Home Assistant available like this in my car has been a big quality of life improvement and I imagine anyone that has remote locks or other automations will appreciate being able to check on the status of and control those items right there on the radio.