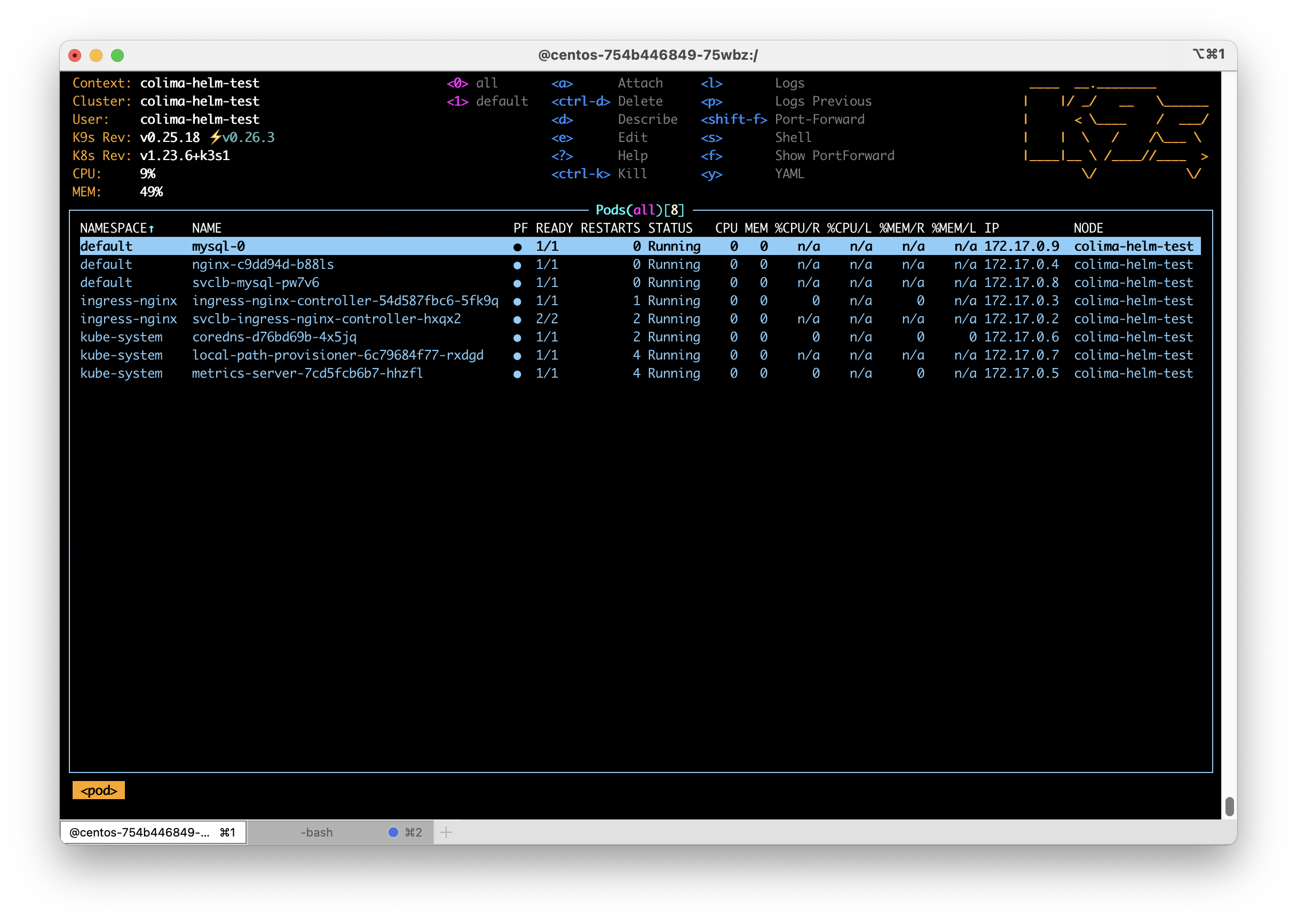
For the past few years I have been using Kubernetes to host a number of services including custom code, WordPress and all manner of other publicly available projects. In this time I have come to rely on a few, what I call, base services that make the experience of running software in Kubernetes just a bit nicer. In this post I’m going to go through what base services I install and a bit on why.
All of the services listed below are installed using helm. I consider Helm the only method for managing applications running in a Kubernetes cluster. Nothing else is able to manage software as well as helm. If a service I want to run in Kubernetes doesn’t have a helm chart I will create one for it.
Almost every Kubernetes setup I use needs to actually service requests from users and this is almost always done using the Ingress system. My preferred ingress controller is the community maintained ingress-nginx. Do not confuse this controller with nginx-ingress, which is put out by nginx.com. I prefer this fully open source controller for its straight forward feature set and configuration system. It has a large number of features and works equally well in both home lab and cloud environments. As an Nginx user anyway I find the configuration very familiar. To install ingress-nginx, I add their repo using helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx. You will find additional information at https://kubernetes.github.io/ingress-nginx/deploy/.
SSL is all but a necessity these days and I have found no better way than to use cert-manager in the cluster. Nearly all of my use cases allow for the usage of a cluster wide, DNS based resolver that allows me to get SSL certs for resources that are not yet publicly accessible or are internal only. By leveraging DNS services from AWS or Cloudflare (or any supported DNS provider) I am able to automatically create and update certificates with very little intervention. To install cert-manager I use the the official helm chart provided by the project using helm repo add jetstack https://charts.jetstack.io. Additional installation directions are available at https://cert-manager.io/docs/installation/helm/.
Speaking of DNS, in clusters where I need to have DNS records pointed towards the cluster I use external-dns. This service looks for ingress entries and manages records in your DNS provider pointing the desired hostname towards your cluster or its external load balancer. I install external-dns using the helm chart by Bitnami. Learn more at https://github.com/bitnami/charts.
Getting logs out of a production cluster is important and assuming you have some place to accept the logs, you won’t generally do better than using fluent-bit. Installation and configuration of fluent-bit is highly dependent on what your logging system is so I recommend reading their documentation on how to get going. Fluent-bit is quite popular and it is usually easy to find examples for whatever your logging system is.
Used by a number of other services, metrics-server gathers basic utilization data from pods and nodes in your cluster. This service is so essential many small Kubernetes systems, like k3s, automatically install this service. I install this service again using Bitnami’s charts available at https://github.com/bitnami/charts.
For managed Kubernetes instances in public clouds I find cluster-autoscaler to be an essential service. When configured correctly, and when combined with metrics-server and properly configured resource settings, cluster-autoscaler will automatically add and remove worker nodes. Information about how to add the cluster-autoscaler helm chart can be found at https://github.com/kubernetes/autoscaler/tree/master/charts/cluster-autoscaler.
These services make Kubernetes much easier and automatic and for that reason I find them to be essential in almost every cluster. What services do you find essential?