Sometimes you need to access Docker on a remote machine. The reasons vary, you just want to manage what is running on a remote system or maybe you want to build for a different architecture. One of the ways that Docker allows for remote access is using ssh. Using ssh is a convenient and secure way to access Docker on a remote machine. If you can ssh to a remote machine using key based authentication then you can access Docker (provided you have your user setup properly). To set this up read about it at https://docs.docker.com/engine/security/protect-access/.
In a previous post, I went over using remote systems to build multi-architecture images using native builders. This post is similar but doesn’t use k3s. Instead, we’ll leverage Docker’s built on context system to add multiple Docker endpoints that we can tie together to create a solution. In fact, for this I am going to use only remote Docker instances from my Mac to build an example image. I assume that you already have Docker installed on your system(s) so I won’t go through that part.
Like in the previous post, I will use the project located at https://github.com/dustinrue/buildx-example as the example project. As a quick note, I have both a Raspberry Pi4 running the 64bit version of PiOS as well as an Intel based system available to me on my local network. I will use both of them to build a very basic multi-architecture Docker image. Multi-architecture Docker images are very useful if you need to target both x86 and Arm based systems, like the Raspberry PI or AWS’s Graviton2 platform.
To get started, I create my first context to add the Intel based system. The command to create a new Docker context that connects to my Intel system looks like this:
docker context create amd64 --docker host=ssh://[email protected]
This creates a context called amd64. I can then use this context by issuing docker context use amd64. After that, all Docker commands I run will be run in that context, on that remote machine. Next, I add my pi4 with a similar command:
docker context create arm64 --docker host=ssh://[email protected]
We now have our two contexts. Next we can create a buildx builder that ties the two together so that we can target it for our multi-arch build. I use these commands to create the builder (note the optional –platform value which will mark that builder for the listed platforms):
docker buildx create --name multiarch-builder amd64 [--platform linux/amd64] docker buildx create --name multiarch-builder --append arm64 [--platform linux/arm64]
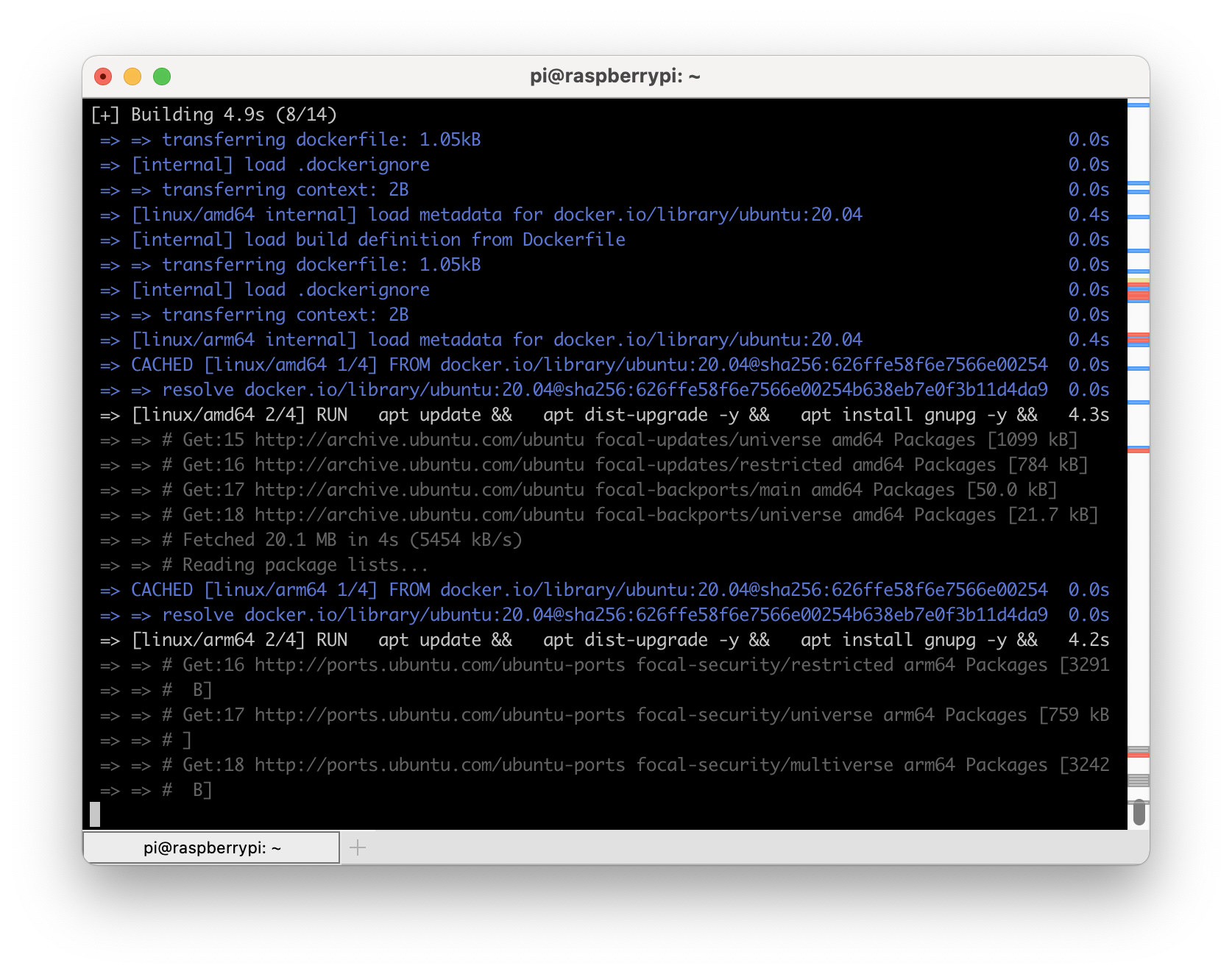
We now have a single builder named multiarch-builder that we can use to build our image. When we ask buildx to build a multi-arch image, it will use the platform that most closely matches the target architecture to do the build. This ensures you get the quickest build times possible.
With the example project cloned, we now build an image that will work for 64bit arm, 32bit arm and 64bit x86 systems with this command:
docker buildx build --builder multiarch-builder -t dustinrue/buildx-example --platform linux/amd64,linux/arm64,linux/arm/v6 .
This command will build our Docker image. If you wish to push the image to a Docker registry, remember to tag the image correctly and add --push to your command. You cannot use --load to load the Docker image into your local Docker registry as that is not supported.
Using another Mac as a Docker context
It is possible to use another Mac as a Docker engine but when I did this I ran into an issue. The Docker command is not in a path that Docker will have available to it when it makes the remote connection. To overcome this, this post will help https://github.com/docker/for-mac/issues/4382#issuecomment-603031242.