In late August of 2021 the company behind Docker Desktop announced their plans to change the licensing model of their popular Docker solution for Mac and Windows. This announcement means many companies who have been using Docker Desktop would now need to pay for the privilege. Thankfully, the open source community is working to create a replacement.
For those not aware, Docker doesn’t run natively on Mac. The Docker Desktop system is actually a small Linux VM running real Docker inside of it and then Docker Desktop does a bunch of magic to make it look and feel like it is running natively on your system. It is for this reason that Docker Desktop users get to enjoy abysmal volume mount performance, the process of shuffling files (especially small ones) requires too much metadata passing to be efficient. Any solution for running Docker on a Mac will need to behave the same way and will inherit the same limitations.
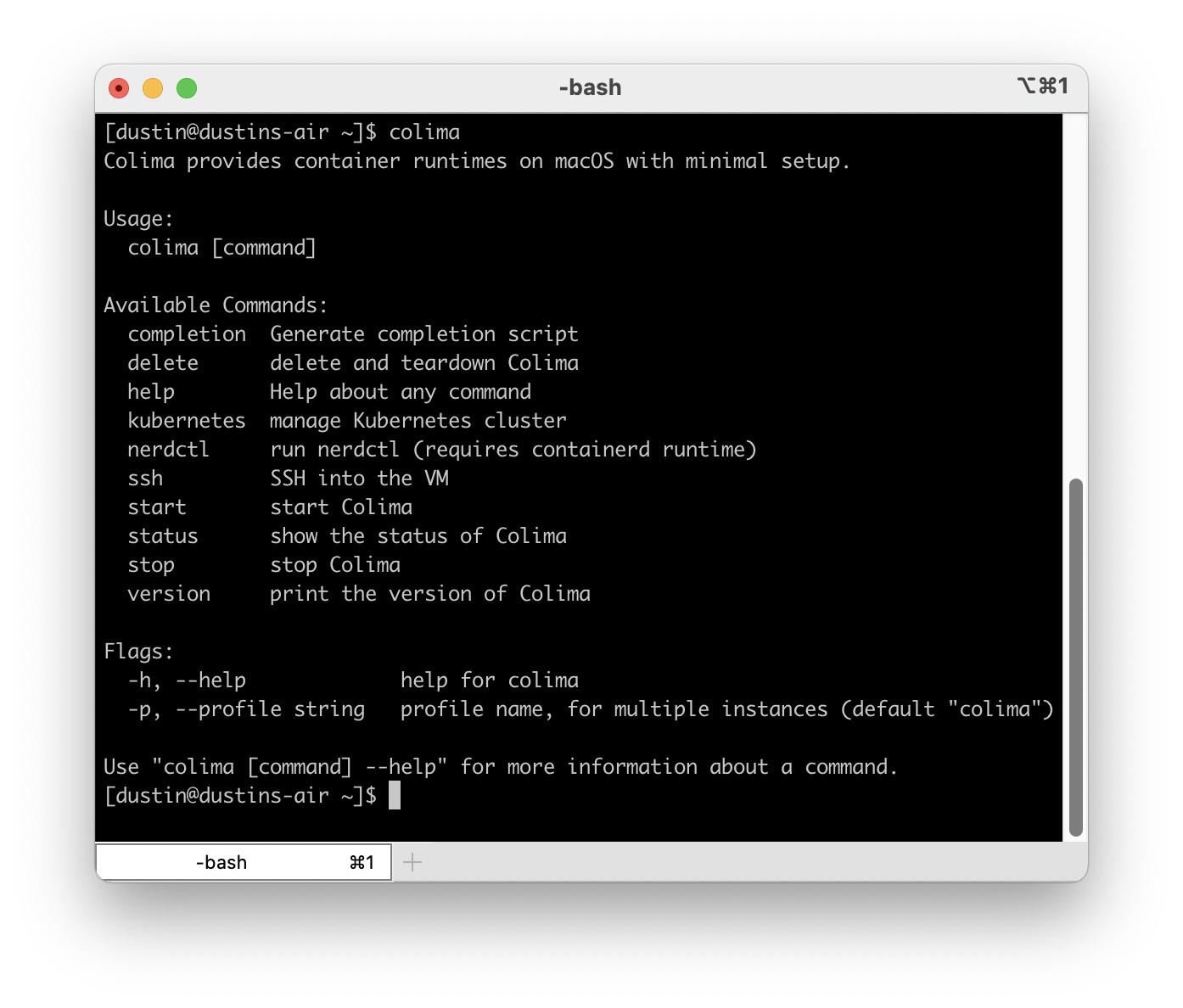
Colima is a command line tool that builds on top of lima to provide a more convenient and complete feeling Docker Desktop replacement and it already shows a lot of promise. Getting started with colima is very simple as long as you already have brew and Xcode command line tools installed. Simply run brew install colima docker kubectl and wait for the process to finish. You don’t need Docker Desktop installed, in fact you should not have it running. Once it is complete you can start it with:
colima start
This will launch a default VM with the docker runtime enabled and configure docker for you. Once it completes you will then have a working installation. That’s literally it! Commands like docker run --rm -ti hello-world will work without issue. You can also build and push images. It’s can do anything you used Docker Desktop for in the past.
Mounting Volumes
Out of the box colima will mount your entire home directory as a read only volume within the colima VM which makes it easily accessible to Docker. Colima is not immune, however, to the performance issues that Docker Desktop struggled with but the read only option does seem to provide reasonable performance.
If, for any reason, you need to have the volumes you mount as read/write you can do that when you start colima. Add --mount <path on the host>:<path visible to Docker>[:w]. For example:
colima start --mount $HOME/project:/project:w
This will mount $HOME/project as /project within the Docker container and it will be writeable. As of this writing the ability to mount a directory read/write is considered alpha quality so you are discouraged from mounting important directories like, your home directory.
In my testing I found that mounting volumes read/write was in fact very slow. This is definitely an area that I hope some magic solution can be found to bring it closer to what Docker Desktop was able to achieve which still wasn’t great for large projects.
Running Kubernetes
Colima also supports k3s based Kubernetes. To get it started issue colima stop and then colima start --with-kubernetes. This will launch colima’s virtual machine, start k3s and then configure kubectl to work against your new, local k3s cluster (this may fail if you have an advanced kubeconfig arrangement).
With Kubernetes running locally you are now free to install apps however you like.
Customizing the VM
You may find the default VM to be a bit on the small side, especially if you decide to run Kubernetes as well. To give your VM more resources stop colima and then start it again with colima start --cpu 6 --memory 6. This will dedicate 6 CPU cores to your colima VM as well as 6GB of memory. You can get a full list of options by simply running colima and pressing enter.
What to expect
This is a very young project that already shows great potential. A lot is changing and currently in the code base is the ability to create additional colima VMs that run under different architectures. For example, you can run arm64 Docker images on your amd64 based Mac or vice versa.
Conclusion
Colima is a young but promising project that can be used to easily replace Docker Desktop and if you are a Docker user I highly recommend giving it a try and providing feedback if you are so inclined. It has the ability to run Docker containers, docker-compose based apps, Kubernetes and build images. With some effort you can also do multi-arch builds (which I’ll cover in a later post). You will find the project at https://github.com/abiosoft/colima.