Since about mid December 2022 I have been running my own private instance of Mastodon. I thought I would detail how I did it and what it has cost me so far.
When I first learned about Mastodon I was excited to get to understand it better, particularly how it is hosted and scaled. For Mastodon, I decided right away that the best way to better my understanding was to host it myself and to do so on my favorite platform, Kubernetes. I started by creating my helm chart (https://github.com/dustinrue/mastodon-helm-chart) and installed the core software in my home lab which consists of k3s. The chart I created is based on the official helm chart (https://github.com/mastodon/chart). I created my own because I, again, wanted to learn about the moving pieces of a Mastodon installation but also because I was unhappy with the official chart integrating Redis and PostgreSQL as dependencies. In addition, it doesn’t break out the Sidekiq processes in a way that makes sense…but more on that later.
Before we can get to deep into what I did, we should probably first discuss some of the major components of a Mastodon instance or server. Mastodon is a collection of services working together to form a full solution which includes:
- A web service which provides the user interface but is also the sort of API server for all things Mastodon. In a full production setup it is important that this be highly available.
- A streaming service which feeds data to the web frontend as it arrives and is processed. This is almost important but doesn’t seem to be critical. In other words, you can survive a bit of downtime here, you’ll just have a less than great experience.
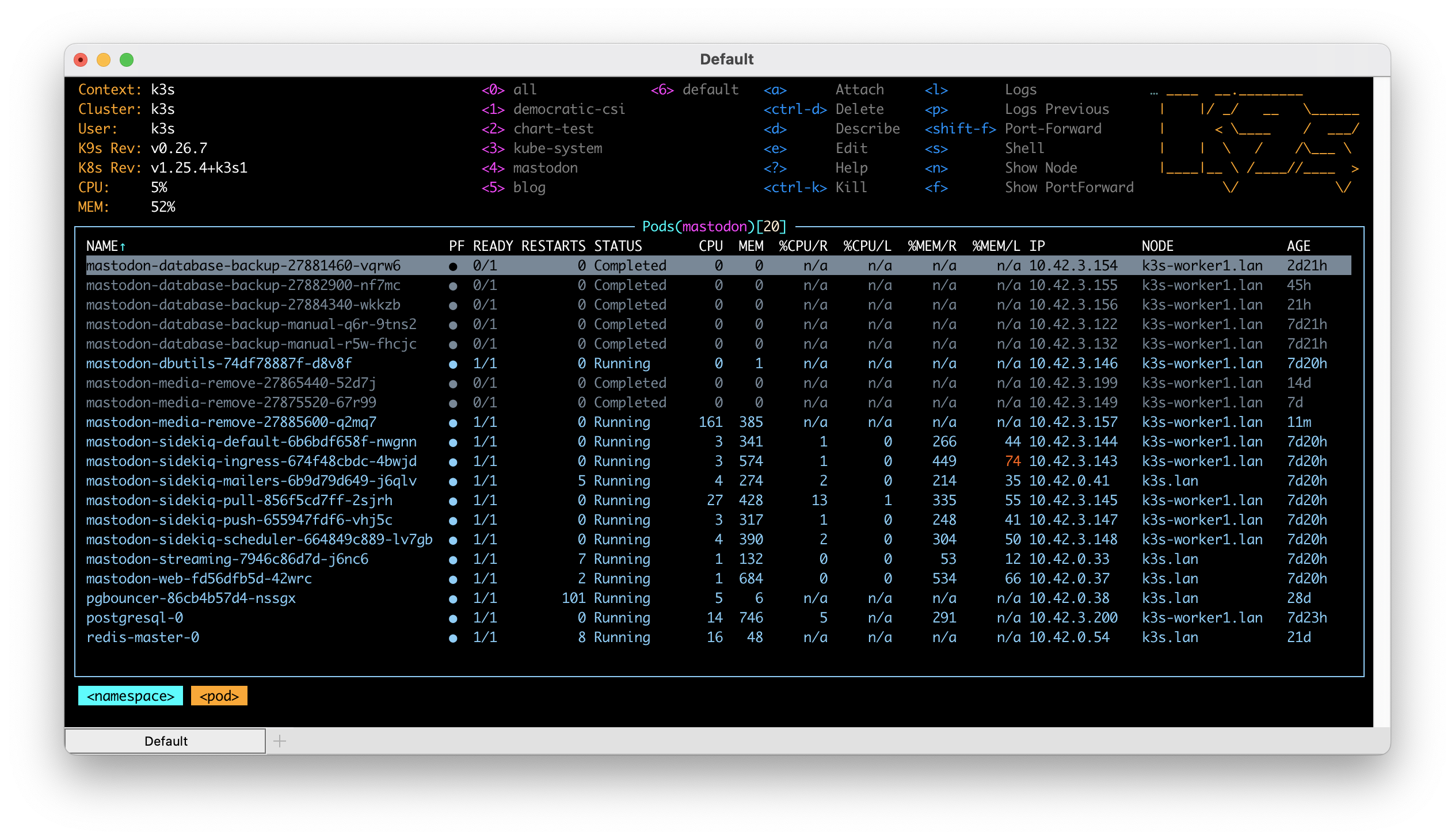
- A number of Sidekiq queues. There are numerous Sidekiq queues which are the heart of how data moves in a Mastodon instance. These queues, as of this writing, include a scheduler, ingress, mailer, push, pull and default. Each queue has a specific purpose and each queue is again not absolutely critical to the availability of your Mastodon instance. This means that you can easily take down each queue temporarily to deal with some issue. While a queue is down know that nothing that queue is responsible for will be processed. The special scheduler queue, if not running, will likely prevent most other queues from doing anything at all.
- Redis is a glue that keeps data flowing between processes. It is also a critical piece to keep running though losing data within it, while not ideal, is ok. Keeping it running is critical because all of the other Mastodon processes expect it to be available and will fail to start without it. In a full production setup I recommend ensuring it is running in a highly available fashion.
- PostgreSQL is the last required piece of software when running Mastodon. Like Redis, it is what I could consider to be critical to your setup. If running a full production setup you will want to cluster it to maintain availability first with performance a secondary consideration.
- You need some system for dealing with email. Mastodon needs to send email for account confirmation and some administrative or moderation work. For my system I am using Send In Blue (https://www.sendinblue.com) which has a free tier.
Mastodon also supports other, optional services which you can read about at https://docs.joinmastodon.org/admin/optional/.
As you can likely see, running Mastodon is not simple yet it isn’t overwhelming either. I believe running Mastodon can be done inexpensively, especially a private instance, but to run it in production correctly, there is definitely a base cost you need to consider so that you can remove as much failure points as possible. In addition, there are many other pieces you will likely want if running a large installation like how to monitor metrics, keeping track of Sidekiq queue depth and processing times and more.
Having spent some time on Mastodon during the great Twitter migration I witnessed some of the struggles of a number of instance admins as a their instances struggled to meet the demands of new users and users who had created accounts before but were suddenly active. I saw a few notable patterns emerge that contributed to their scaling woes including:
- Not using a CDN or object storage system initially
- Not installing pgbouncer in front of PostgreSQL
- Not installing Sidekiq into separate processes running each queue
There are some really excellent guides and references on how to scale Mastodon (https://hazelweakly.me/blog/scaling-mastodon/ to name but one) but many of the recommendations will require you to do or have done one, if not all, of the above mentioned steps. Each of these items are disruptive in a way that you probably do not want to be trying to handle them while in a panic of trying to get your instance running again. If you are running or plan to run a public instance where you allow anyone to sign up then I highly recommend getting at least those three items out of the way from day one. Doing so will help ensure that scaling up from there is much, much easier as most items will then become adding additional servers to run more Sidekiq processes or tuning parameters.
When I created my helm chart, I took these lessons and applied them as conscious decisions in the design of the chart. Though not at all necessary for a small or single user instance, my chart breaks out all of the current Sidekiq queues into separate processes. This layout ensures the hard work of separating the processes out is done and the rest is a matter of scaling and tuning.
As of this writing, my helm chart also installs a weekly cronjob to clean up media files and, optionally, a cronjob for backing up the database to some shared storage in your Kubernetes cluster. Though it is ultimately incomplete, I feel the helm chart is a good start.
As for actually running Mastodon for myself I created a subdomain for my instance to live at. I then installed Mastodon, using my helm chart, into my k3s cluster. Ignoring the cost of my ISP and the computers I have, running Mastodon is quite minimal. My home lab provides everything I need to make Mastodon work including persistent storage using TrueNAS. For media storage, I created a Cloudflare R2 bucket and URL for public access. Mastodon is configured to send media content to R2 which is then served from the CDN URL. This keeps all of the heavy storage separate from the rest of the system. My last bill for R2 was just $0.06 which was for the approximately 20GB of content I have stored there. I do expect my next bill to be more because the average amount of data stored in R2 will be higher.
Since my installation is just a private one, I installed PostgreSQL and Redis as single instances within my k3s cluster. Both instances are extremely basic Bitnami based installed using their available helm charts. PostgreSQL is backed by persistent storage provided by TrueNAS. For email, my k3s cluster runs an installation of Postfix. Postfix is configured to send email through Send In Blue and services that I run in my cluster are configured to talk to Postfix. This allows me to have a single mail relay that I need to maintain the configuration for.
Ingress is provided by Cloudflare and cloudflared tunnels. A tunnel is configured on a different VM I have running and then configured in the Cloudfare side on how to route traffic to the Kube cluster with the correct hostname included.
All said, this setup has proven reliable for me since mid December. In a future post I’ll discuss how I got my private instance to feel a bit more included in the Fediverse by adding relays. Please leave a comment if you feel I missed something or got something wrong.