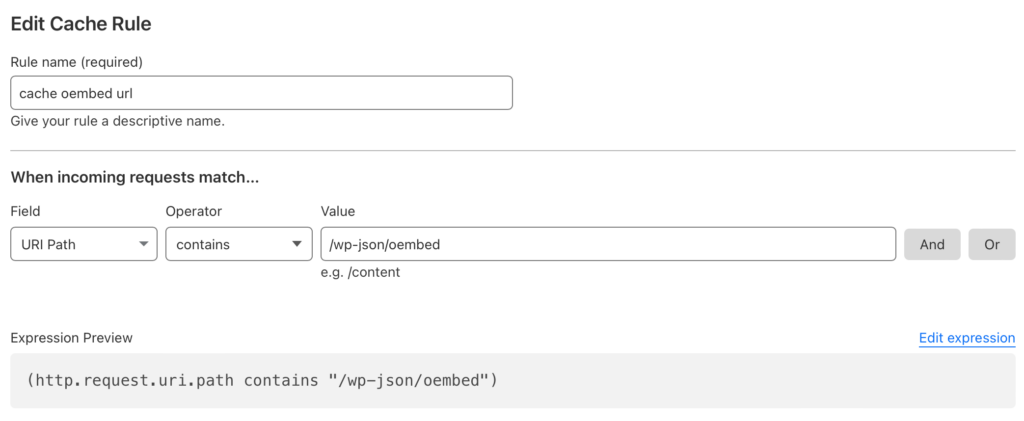
Some time ago I removed Google Analytics to avoid the tracking that came along with it and it all being tied to Google. I also wasn’t overly concerned about how much traffic my site got. I write here and if it helps someone then great but I’m not out here to play SEO games. Recently, however, I heard of a new self hosted option called Umami that claims to respect user privacy and is GDPR compliant. In this post I will go through how I set it up on the site.
Umami supports both PostgreSQL and MySQL. The installation resource I used, discussed below, defaults to PostgreSQL as the datastore and I opted to stick with that. PostgreSQL is definitely not a strong skill of mine and I struggled to get things running initially. Although I have PostgreSQL installed on a VM already for my Mastodon instance, I had to take some additional steps to get PostreSQL ready for Umami. After some trial and error I was able to get Umami running.
My installation of PostreSQL is done using the official postgres.org resources which you can read about at https://www.postgresql.org. In addition to having PostgreSQL itself installed as a service I also needed to install postgresql15-contrib in order to add pgcrypto support. pgcrypto support wasn’t something I found documented in the Umami setup guide but the software failed to start successfully without it and an additional step detailed below. Below is how I setup my user for Umami with all commands run as the postgres user or in psql. Some info was changed to be very generic, you should change it to suit your environment:
- cli:
createdb umami - psql:
CREATE ROLE umami WITH LOGIN PASSWORD 'password’; - psql:
GRANT ALL PRIVILEGES ON DATABASE umami TO umami; - psql:
\c umamito select the umami database - psql:
CREATE EXTENSION IF NOT EXISTS pgcrypto; - psql:
GRANT ALL PRIVILEGES ON SCHEMA public TO umami;
With the above steps taken care of you can continue on.
Since I am a big fan of using Kubernetes whenever I can, my Umami instance is installed into my k3s based Kubernetes cluster. For the installation of Umami I elected to use a Helm chart by Christian Huth which is available at https://github.com/christianhuth/helm-charts and worked quite well for my purposes. Follow Christian’s directions for adding the helm chart repository and read up on the available options. Below is the helm values I used for installation:
ingress:
# -- Enable ingress record generation
enabled: true
# -- IngressClass that will be be used to implement the Ingress
className: "nginx"
annotations:
cert-manager.io/cluster-issuer: letsencrypt-production
# -- Additional annotations for the Ingress resource
hosts:
- host: umami.dustinrue.com
paths:
- path: /
pathType: ImplementationSpecific
# -- An array with the tls configuration
tls:
- secretName: umami-tls
hosts:
- umami.dustinrue.com
umami:
# -- Disables users, teams, and websites settings page.
cloudMode: ""
# -- Disables the login page for the application
disableLogin: ""
# -- hostname under which Umami will be reached
hostname: "0.0.0.0"
postgresql:
# -- enable PostgreSQL™ subchart from Bitnami
enabled: false
externalDatabase:
type: postgresql
database:
# -- Key in the existing secret containing the database url
databaseUrlKey: "database-url"
# -- use an existing secret containing the database url. If none given, we will generate the database url by using the other values. The password for the database has to be set using `.Values.postgresql.auth.password`, `.Values.mysql.auth.password` or `.Values.externalDatabase.auth.password`.
existingSecret: "umami-database-url"The notable changes I made from the default values provided is I enabled ingress and set my hostname for it as required. I also set cloudMode and diableLogin to empty so that these items were not disabled. Of particular note, leaving hostname at the default value is the correct option as setting it to my hostname broke the startup process. Next, I disabled the postgresql option. This disables the installation of PostgreSQL as a dependent chart since I already had PostreSQL running.
The last section is how I defined my database connection information. To do this, I created a secret using kubectl create secret generic umami-database-url -n umami and then edited the secret with kubectl edit secret umami-database-url -n umami. In the secret, I added a data section with base64 encoded string for “postgresql://umami:[email protected]:5432/umami”. The secret looks like this:
apiVersion: v1
data:
database-url: cG9zdGdyZXNxbDovL3VtYW1pOnBhc3N3b3JkQDEwLjAuMC4xOjU0MzIvdW1hbWk=
kind: Secret
metadata:
name: umami-database-url
namespace: umami
type: OpaqueUmami was then installed into my cluster using helm install -f umami-values.yaml -n umami umami christianhuth/umami which brought it up. After a bit of effort on the part of Umami to initialize the database I was ready to login using the default username/password of admin/umami.
I setup a new site in Umami per the official directions and grabbed some information that is required for site setup from the tracking code page.
Configuring WordPress
Configuring WordPress to send data to Umami was very simple. I added the integrate-umami plugin to my installation, activated the plugin and then went to the settings page to input the information I grabbed earlier. My settings page looks like this:

With this information saved, the tracking code is now inserted into all pages of the site and data is sent to Umami.
Setting up Umami was a bit cumbersome for me initially but that was mostly because I am unfamiliar with PostgreSQL in general and the inline documentation for the Helm chart is not very clear. After some trial and error I was able to get my installation working and I am now able to track at least some metrics for this site. In fact, Umami allows me to share a public URL for others to use. The stats for this site is available at https://umami.dustinrue.com/share/GadqqMiFCU8cSC7U/Blog.